AI Dubbing Evaluation Methodology
AI video dubbing instantly converts media dialogue into another language, perfectly aligning cloned voices and lip movements with the speaker while preserving their vocal identity. By automating what once demanded weeks of studio labor, it slashes both time and operational overhead.
How AI Dubbing Works
At it’s core, AI dubbing is the orchestration of three components: transcription, translation, and text-to-speech.
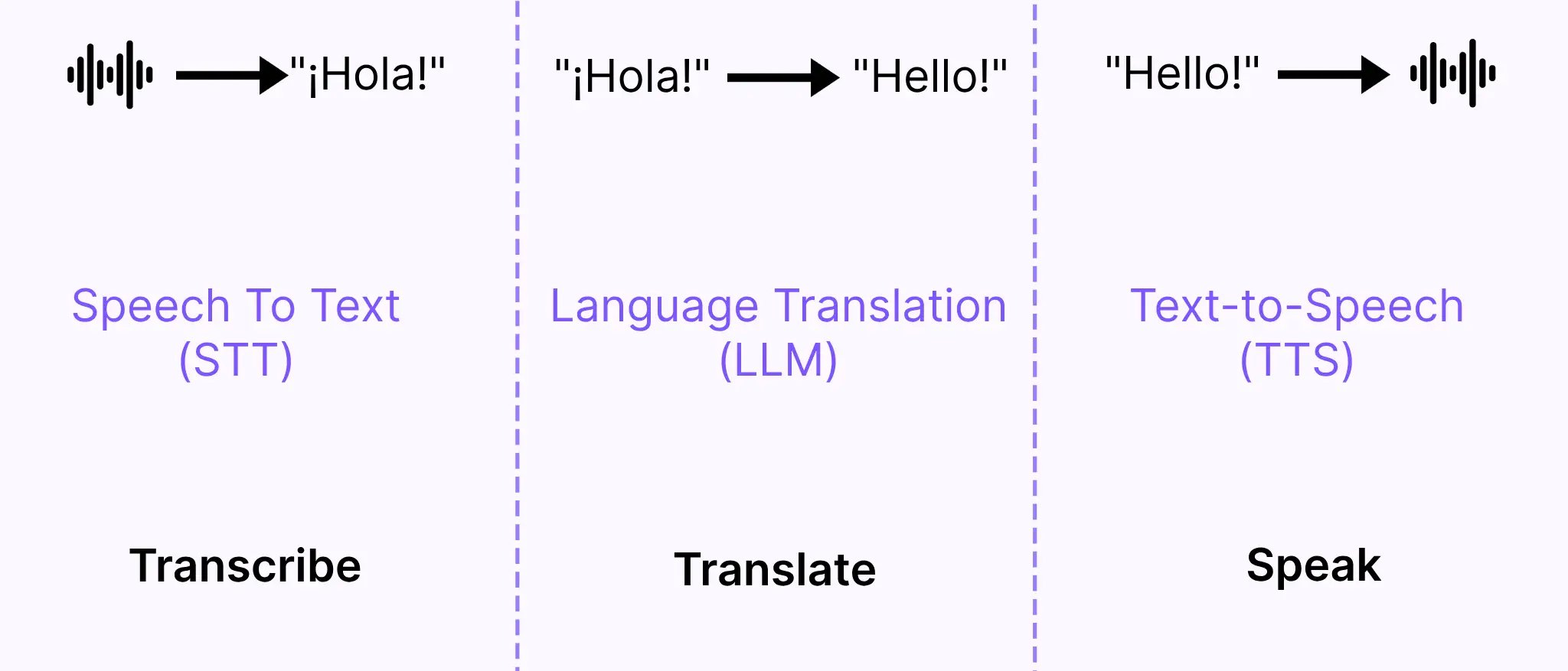
These three individual components are available off-the-shelf through a host of open-source and proprietary speech-to-text, LLM, and text-to-speech models. Sieve takes a variety of these components, tunes them for greater multi-lingual performance, applies the right pre and post-processing between them, and orchestrates a pipeline that delivers the highest quality dubs across a variety of languages and contexts.
Audio to Text
Language Conversion
Voice Synthesis
Sieve pulls all these pieces together, ensuring a smooth & natural output dub (in addition to providing you with a simple set of parameters to manage these inner-workings).
How to evaluate it?
Evaluating a dubbing stack along the following axes surfaces weaknesses that one-number MOS scores hide. Together they cover linguistic accuracy, acoustic realism, temporal precision, and multi-speaker coherence—the pillars that make a dub feel native rather than “overlayed.”
Translation Quality
Measures how faithfully the dub preserves meaning, tone, and cultural nuance. A mistranslated joke or idiom can break immersion or even offend viewers. Best-in-class systems pass rich context (preceding sentences, speaker persona, domain glossaries) to the MT model and use post-edit heuristics to keep proper names and brand terms intact.
Grammar, Syntax & Terminology
Even when literal meaning is correct, bad word order or the wrong technical term shouts "machine translation." Clean grammar and domain-specific lexicon signal professionalism—crucial for education, medical, or enterprise content. Evaluation here checks whether the pipeline's LLM prompt-engineering and custom dictionaries are doing their job.
Voice Cloning & Speaker Identity
Viewers expect each on-screen character to "sound like themselves"—same gender, age, timbre, emotional register. High-fidelity cloning demands enough clean reference audio, adaptive similarity weights, and fallback voices that still feel plausible. Poor identity transfer is where most cheap dubs fall apart.
Naturalness & Accent
Prosody (stress, rhythm, intonation) and a region-appropriate accent make the dub feel truly human. A TTS with flat pacing or a mismatched accent reminds the audience they're hearing a robot. Evaluators listen for lifelike pitch contours, breathing, and localized phoneme coloration.
Timing, Sync & Speed Adjustments
Audio must land inside each shot's mouth movements and scene cuts—without chipmunking or noticeable slow-downs. Precision requires phoneme-duration prediction, fine-grained atempo stretching, and word-level lip-sync alignment. If lips drift or pauses feel unnatural, viewers instantly notice.
Clarity & Noise Robustness
All syllables must be intelligible whether the original video is a quiet lecture or a windy street interview. That means front-end denoising, adaptive leveling, and loudness normalization so the dub sits cleanly on top of the restored ambience. Clarity testing hunts for clipped consonants, buried vowels, and background hiss.
Multispeaker Handling
Reality-grade content often has panels, podcasts, or overlapping dialogue. Accurate diarization, per-speaker translation context, and separate voice clones prevent identity swaps or merged lines. Proper handling preserves conversational flow and lets downstream analytics still identify who said what.
Human Evaluations
To evaluate the quality of various AI dubbing providers, we hired 10 native speakers for each target language of interest. These evaluators reviewed a diverse set of dubbed videos generated by different providers using the rubric above.
Each aspect was rated on a 1–5 scale to provide detailed, comparative feedback across different providers. We decided to use native speakers since they were able to assess not just the technical accuracy but also the cultural and emotional nuances of each dubbing output.
We also asked evaluators whether the dubbing felt human and immersive, and if they would recommend using it, giving us both granular insights and a high-level sense of performance. This structured, human-driven approach allowed us to fairly compare the strengths and weaknesses of different AI dubbing solutions.